flex lexical analyser
| Developer(s) | Vern Paxson |
|---|---|
| Stable release | 2.5.35 / February 26, 2008 |
| Operating system | Unix-like |
| Type | Lexical analyzer generator |
| License | BSD license |
| Website | http://flex.sourceforge.net/ |
flex (fast lexical analyzer generator) is a free software alternative to lex.[1] It is frequently used with the free Bison parser generator. Unlike Bison, flex is not part of the GNU Project.[2] Flex was written in C by Vern Paxson around 1987. He was translating a Ratfor generator, which had been led by Jef Poskanzer.[3]
A similar lexical scanner for C++ is flex++, which is included as part of the flex package. At the moment, flex supports generating code only for C and C++ (see flex++). The generated code does not depend on any runtime or external library except for a memory allocator (malloc or a user-supplied alternative) unless the input also depends on it. This can be useful in embedded and similar situations where traditional operating system or C runtime facilities may not be available.
Contents |
Example lexical analyzer
This is an example of a scanner which does not make use of Flex (written in C) for the instructional programming language PL/0.
The symbols recognized are: '+', '-', '*', '/', '=', '(', ')', ',', ';', '.', ':=', '<', '<=', '<>', '>', '>='; numbers: 0-9 {0-9}; identifiers: a-zA-Z {a-zA-Z0-9} and keywords: begin, call, const, do, end, if, odd, procedure, then, var, while.
External variables used:
FILE *source /* The source file */ int cur_line, cur_col, err_line, err_col /* For error reporting */ int num /* Last number read stored here, for the parser */ char id[] /* Last identifier read stored here, for the parser */ Hashtab *keywords /* List of keywords */
External routines called:
error(const char msg[]) /* Report an error */ Hashtab *create_htab(int estimate) /* Create a lookup table */ int enter_htab(Hashtab *ht, char name[], void *data) /* Add an entry to a lookup table */ Entry *find_htab(Hashtab *ht, char *s) /* Find an entry in a lookup table */ void *get_htab_data(Entry *entry) /* Returns data from a lookup table */ FILE *fopen(char fn[], char mode[]) /* Opens a file for reading */ fgetc(FILE *stream) /* Read the next character from a stream */ ungetc(int ch, FILE *stream) /* Put-back a character onto a stream */ isdigit(int ch), isalpha(int ch), isalnum(int ch) /* Character classification */
External types:
Symbol /* An enumerated type of all the symbols in the PL/0 language */ Hashtab /* Represents a lookup table */ Entry /* Represents an entry in the lookup table */
Scanning is started by calling init_scan, passing the name of the source file. If the source file is successfully opened, the parser calls getsym repeatedly to return successive symbols from the source file.
The heart of the scanner, getsym, should be straightforward. First, whitespace is skipped. Then the retrieved character is classified. If the character represents a multiple-character symbol, additional processing must be done. Numbers are converted to internal form, and identifiers are checked to see if they represent a keyword.
int read_ch(void) { int ch = fgetc(source); cur_col++; if (ch == '\n') { cur_line++; cur_col = 0; } return ch; } void put_back(int ch) { ungetc(ch, source); cur_col--; if (ch == '\n') cur_line--; } Symbol getsym(void) { int ch; while ((ch = read_ch()) != EOF && ch <= ' ') ; err_line = cur_line; err_col = cur_col; switch (ch) { case EOF: return eof; case '+': return plus; case '-': return minus; case '*': return times; case '/': return slash; case '=': return eql; case '(': return lparen; case ')': return rparen; case ',': return comma; case ';': return semicolon; case '.': return period; case ':': ch = read_ch(); return (ch == '=') ? becomes : nul; case '<': ch = read_ch(); if (ch == '>') return neq; if (ch == '=') return leq; put_back(ch); return lss; case '>': ch = read_ch(); if (ch == '=') return geq; put_back(ch); return gtr; default: if (isdigit(ch)) { num = 0; do { /* no checking for overflow! */ num = 10 * num + ch - '0'; ch = read_ch(); } while ( ch != EOF && isdigit(ch)); put_back(ch); return number; } if (isalpha(ch)) { Entry *entry; id_len = 0; do { if (id_len < MAX_ID) { id[id_len] = (char)ch; id_len++; } ch = read_ch(); } while ( ch != EOF && isalnum(ch)); id[id_len] = '\0'; put_back(ch); entry = find_htab(keywords, id); return entry ? (Symbol)get_htab_data(entry) : ident; } error("getsym: invalid character '%c'", ch); return nul; } } int init_scan(const char fn[]) { if ((source = fopen(fn, "r")) == NULL) return 0; cur_line = 1; cur_col = 0; keywords = create_htab(11); enter_htab(keywords, "begin", beginsym); enter_htab(keywords, "call", callsym); enter_htab(keywords, "const", constsym); enter_htab(keywords, "do", dosym); enter_htab(keywords, "end", endsym); enter_htab(keywords, "if", ifsym); enter_htab(keywords, "odd", oddsym); enter_htab(keywords, "procedure", procsym); enter_htab(keywords, "then", thensym); enter_htab(keywords, "var", varsym); enter_htab(keywords, "while", whilesym); return 1; }
Now, contrast the above code with the code needed for a flex generated scanner for the same language:
%{
#include "y.tab.h"
%}
digit [0-9]
letter [a-zA-Z]
%%
"+" { return PLUS; }
"-" { return MINUS; }
"*" { return TIMES; }
"/" { return SLASH; }
"(" { return LPAREN; }
")" { return RPAREN; }
";" { return SEMICOLON; }
"," { return COMMA; }
"." { return PERIOD; }
":=" { return BECOMES; }
"=" { return EQL; }
"<>" { return NEQ; }
"<" { return LSS; }
">" { return GTR; }
"<=" { return LEQ; }
">=" { return GEQ; }
"begin" { return BEGINSYM; }
"call" { return CALLSYM; }
"const" { return CONSTSYM; }
"do" { return DOSYM; }
"end" { return ENDSYM; }
"if" { return IFSYM; }
"odd" { return ODDSYM; }
"procedure" { return PROCSYM; }
"then" { return THENSYM; }
"var" { return VARSYM; }
"while" { return WHILESYM; }
{letter}({letter}|{digit})* {
yylval.id = (char *)strdup(yytext);
return IDENT; }
{digit}+ { yylval.num = atoi(yytext);
return NUMBER; }
[ \t\n\r] /* skip whitespace */
. { printf("Unknown character [%c]\n",yytext[0]);
return UNKNOWN; }
%%
int yywrap(void){return 1;}
About 50 lines of code for flex versus about 100 lines of hand-written code.
Issues
Time complexity
A Flex lexical analyzer sometimes has time complexity 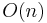 in the length of the input. That is, it performs a constant number of operations for each input symbol. This constant is quite low: GCC generates 12 instructions for the DFA match loop. Note that the constant is independent of the length of the token, the length of the regular expression and the size of the DFA.
in the length of the input. That is, it performs a constant number of operations for each input symbol. This constant is quite low: GCC generates 12 instructions for the DFA match loop. Note that the constant is independent of the length of the token, the length of the regular expression and the size of the DFA.
However, one optional feature of Flex can cause Flex to generate a scanner with non-linear performance: The use of the REJECT macro in a scanner with the potential to match extremely long tokens. In this case, the programmer has explicitly told flex to "go back and try again" after it has already matched some input. This will cause the DFA to backtrack to find other accept states. In theory, the time complexity is 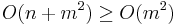 where
where 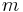 is the length of the longest token (this reverts to if tokens are "small" with respect to the input size).[4] The REJECT feature is not enabled by default, and its performance implications are thoroughly documented in the Flex manual.
is the length of the longest token (this reverts to if tokens are "small" with respect to the input size).[4] The REJECT feature is not enabled by default, and its performance implications are thoroughly documented in the Flex manual.
Reentrancy
By default the scanner generated by Flex is not reentrant. This can cause serious problems for programs that use the generated scanner from different threads. To overcome this issue there are options that Flex provides in order to achieve reentrancy. A detailed description of these options can be found in the Flex manual.[5]
Usage under non-Unix environments
Normally the generated scanner contains references to unistd.h header file which is Unix specific. To avoid generating code that includes unistd.h, %option nounistd should be used. Another issue is the call to isatty (a Unix library function), which can be found in the generated code. The %option never-interactive forces flex to generate code that doesn't use isatty. These options are detailed in the Flex manual.[6]
Using flex from other languages
Flex can only generate code for C and C++. To use the scanner code generated by flex from other languages a language binding tool such as SWIG can be used.
Flex++
Flex++ is a tool for creating a language parsing program. A parser generator creates a language parsing program. It is a general instantiation of the flex program.
These programs perform character parsing, and tokenizing via the use of a deterministic finite automata or Deterministic finite automaton (DFA). A DFA (or NDFA) is a theoretical machine accepting regular languages. These machines are a subset of the collection of Turing machines. DFAs are equivalent to read only right moving Turing Machines or NDFAs. The syntax is based on the use of Regular expressions.
Flex provides two different ways to generate scanners. It primarily generates C code to be compiled as opposed to C++ libraries and code. Flex++, an extension of flex, is used for generating C++ code and classes. The Flex++ classes and code require a C++ compiler to create lexical and pattern-matching programs. Flex, the alternative language parser, defaults to generating a parsing scanner in C code. The Flex++ generated C++ scanner includes the header file FlexLexer.h, which defines the interfaces of the two C++ generated classes.
Flex creators
Vern Paxson, with the help of many ideas and much inspiration from Van Jacobson.
See also
- John Levine, flex & bison, O'Reilly and Associates
- M. E. Lesk and E. Schmidt, LEX - Lexical Analyzer Generator
- Alfred Aho, Ravi Sethi and Jeffrey Ullman, Compilers: Principles, Techniques and Tools, Addison-Wesley (1986). Describes the pattern-matching techniques used by flex (deterministic finite automata)
References
- ^ Levine, John (August 2009). flex & bison. O'Reilly Media. pp. 304. ISBN 978-0-596-15597-1. http://oreilly.com/catalog/9780596155988.
- ^ Is flex GNU or not?, flex FAQ
- ^ When was flex born?, flex FAQ
- ^ http://flex.sourceforge.net/manual/Performance.html (last paragraph)
- ^ http://flex.sourceforge.net/manual/Reentrant.html
- ^ http://flex.sourceforge.net/manual/Code_002dLevel-And-API-Options.html